Si può ottimizzare l’architettura RISC-V a singolo colpo di clock e senza pipeline in quanto in ogni fase dell’esecuzione delle istruzioni la CPU è inutilizzata per l’80%, perché le unità funzionali si attivano una alla volta. L’idea è di far eseguire contemporaneamente fasi diverse di più istruzioni (max 5) in modo che più unità funzionali possibili siano occupate in un determinato momento.
Come funziona la pipeline
| istruzioni | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| 1 | IF | ID | EXE | MEM | WB | ||||
| 2 | IF | ID | EXE | MEM | WB | ||||
| 3 | IF | ID | EXE | MEM | WB | ||||
| 4 | IF | ID | EXE | MEM | WB | ||||
| 5 | IF | ID | EXE | MEM | WB |
La fase Instruction Fetch si può sovrapporre alla fase Instruction Decode, cioè possiamo calcolare il prossimo valore del PC (+=4) senza sapere di che tipo è la prossima istruzione, perché in RISC-V tutte le istruzioni hanno la stessa lunghezza.
Questa sovrapposizione delle fasi può introdurre delle criticità, dette hazard.
Il calcolo del periodo di clock cambia, non bisogna più vedere la durata totale dell’istruzione più lenta, ma quella della singola fase più lenta.
Quantificare l’aumento della velocità di esecuzione
Senza pipeline: periodo di clock di 800 ps in base alla durata totale dell’istruzione più lenta. Con pipeline: periodo di clock di 200 ps in base alla durata della fase più lenta (IF e MEM). (In media) la velocità di esecuzione delle istruzioni è quadruplicata.
| istruzione | IF | ID | EXE | MEM | WB | totale |
|---|---|---|---|---|---|---|
lw | 200 | 100 | 200 | 200 | 100 | 800 |
sw | 200 | 100 | 200 | 200 | 700 | |
| Tipo R | 200 | 100 | 200 | 100 | 600 | |
beq | 200 | 100 | 200 | 500 |
Per valutare l’efficienza di una sequenza di informazioni, con o senza pipeline, bisogna introdurre il throughput, cioè il numero di istruzioni completate (in una determinata situazione) diviso il numero di fasi per completarle.
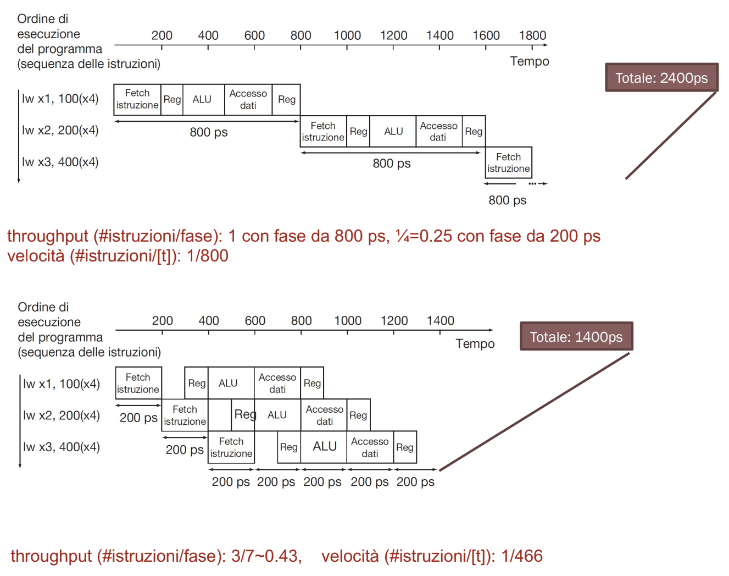
Senza pipeline: throughput = 3/15 = 0.2 Con pipeline: throughput = 3/7 = 0.43
Come costruire la pipeline
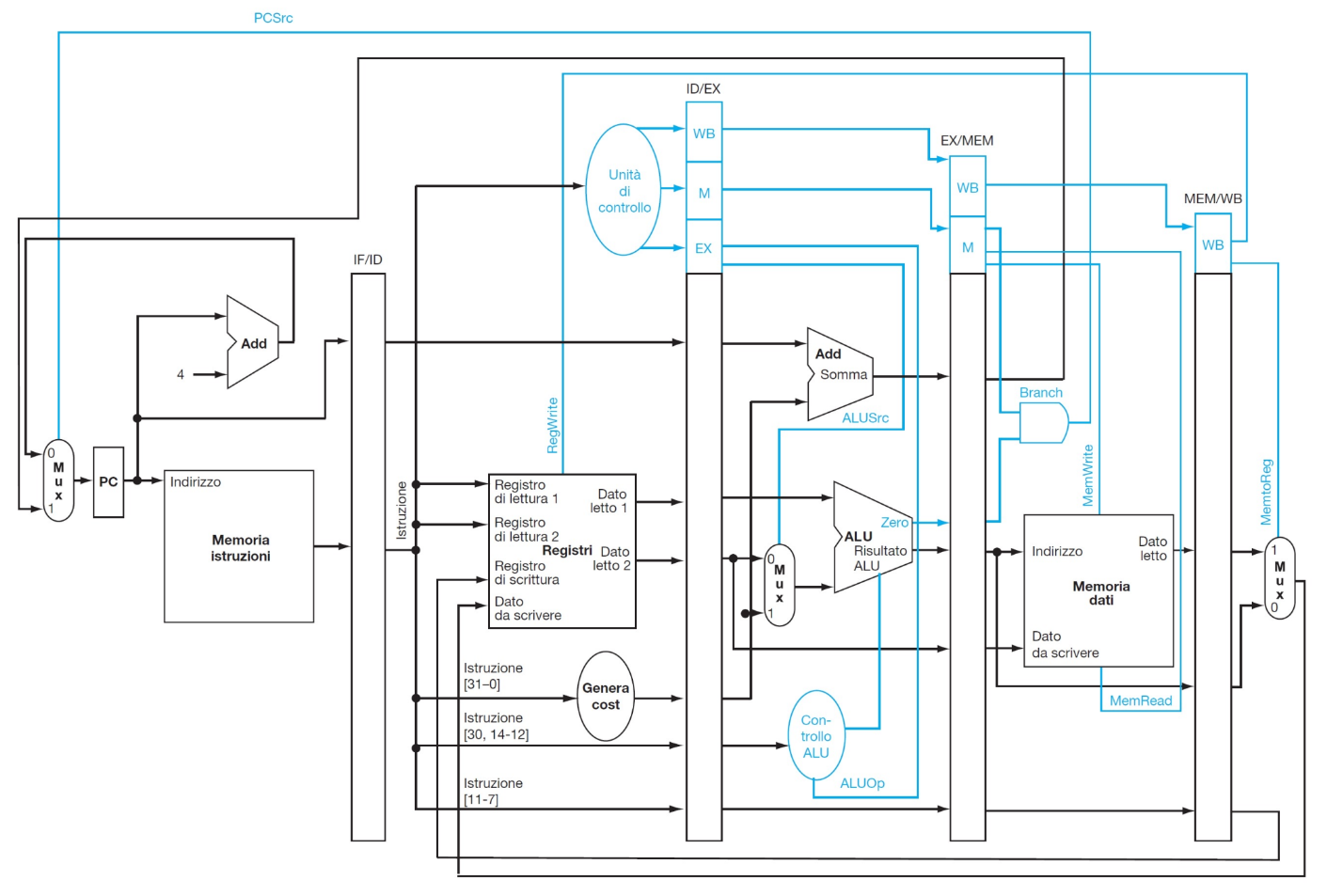
Innanzitutto bisogna considerare che ciascuna fase riceve informazioni e segnali di controllo e ne passa altre alla successiva, inoltre i segnali necessari devono restare stabili (quindi memorizzati) durante tutta la fase, cambiando solo al fronte di salita del clock.
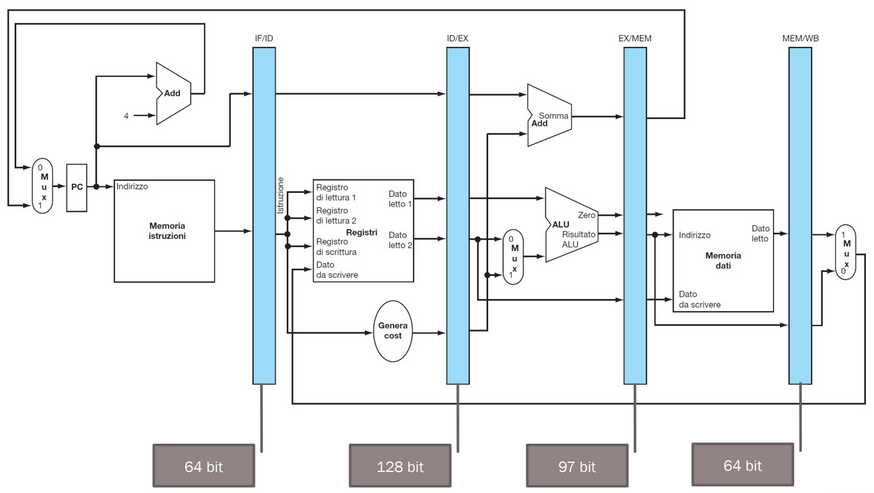
La soluzione è separare ciascuna fase dalla successiva con un registro, che riceve e memorizza tutti i dati (letti dai registri o dalla parte immediata) e i segnali di controllo (generati dalla Control Unit) della stessa istruzione.
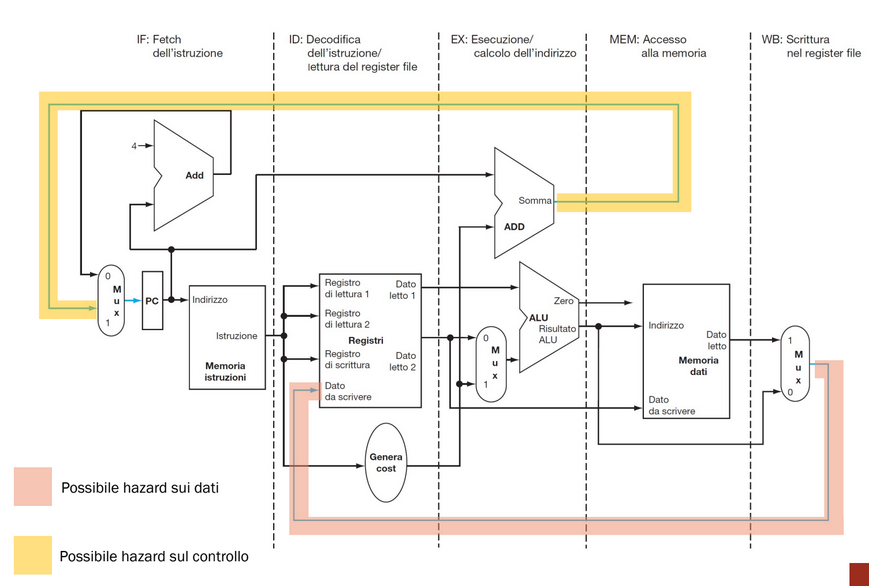
Il problema di questa configurazione è che il dato da scrivere nel registro di scrittura nella fase Write Back è cambiato durante l’esecuzione dell’istruzione, quindi è sbagliato: infatti proviene dal registro IF/ID, che sta già iniziando la fase dell’istruzione che sta 3 cicli dopo quella giusta:
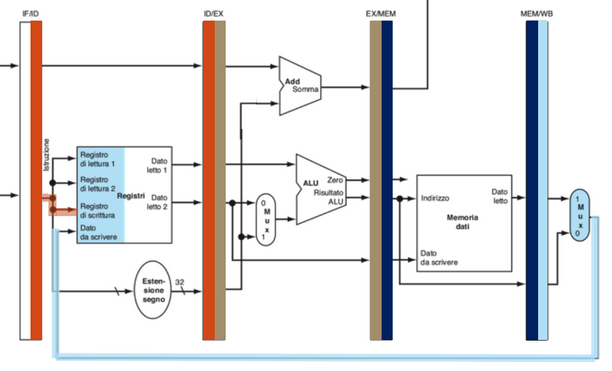
Ciò si può risolvere facendo in modo che tutte le informazioni e i segnali di controllo siano sempre memorizzate nel registro precedente della pipeline, per operare sui dati giusti:
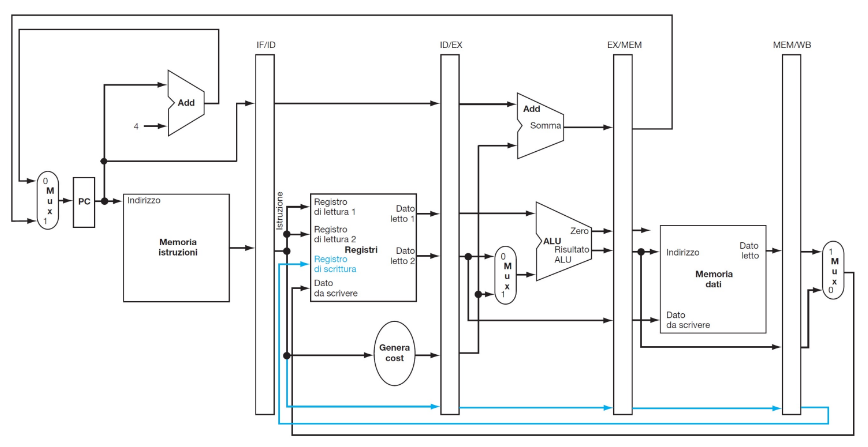
CPU quasi completa